
Het compressie-team! Andrew, Lars en Thomas (geanonimiseerd).
Hackathon-project: compressie-algoritme
In dit verslagje zit expres geen codevoorbeeld en verklappen we niets over de stappen die wij gebruikten... daardoor kun je dit project zelf ook misschien een keer doen!
Wat is comprimeren?
Het comprimeren van bestanden zonder kwaliteitsverlies betekent eigenlijk: via een stappenplan een reeks van tekens (origineel bestand A) zo herschrijven dat er minder tekens nodig zijn (gecomprimeerd bestand B), terwijl het wel weer "uitgepakt" kan worden via een tweede stappenplan om precies dezelfde reeks van tekens weer terug te krijgen (bestand C is gelijk aan bestand A).
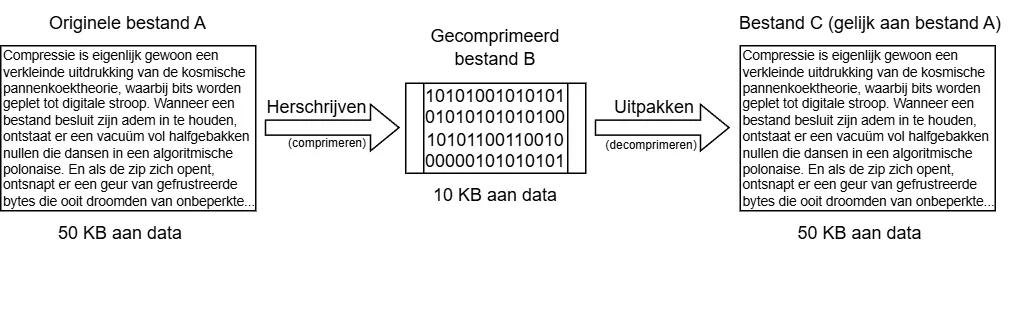
Welke vragen spelen er een rol bij comprimeren?
Er bestaan al compressie-algoritmes, maar wij hadden daar expres niets over opgezocht, omdat het proces van ontdekken en nadenken juist heel leuk is. Vragen die we tijdens de hackathon in gedachten kregen, waren bijvoorbeeld:
- Is het handig om het algoritme eerst het hele bestand door te laten lezen en een dictionary van verzamelde informatie te maken, voordat het algoritme start aan het schrijven van het (gecomprimeerde) bestand? Het zou voor performance beter zijn als we dat niet zouden doen. Om maximale compressie te bereiken, zal het juist wel beter zijn.
- Stel dat we informatie over de gebruikte teken-reeksen binnen de totale teken-reeks verzamelen. Wat beschouwen we dan als "teken"? Gaan we op byte-niveau kijken of zoeken we naar patronen in de reeks van de nullen en enen?
- Kijken we naar pure herhaling, of ook naar andere patronen?
- Hoe richten wij ons dictionary, of onze "legenda", van verzamelde informatie in? Stoppen we daar elk teken in dat we tegenkomen? Stoppen we daar vervolgens ook elk voorkomend tweetal van tekens in, elk drietal, et cetera? Wat voor ID geven we elk element dat we in het dictionary stoppen?
- Als we een dictionary/legenda gebruiken, moet daarvan dan ook iets in het gecomprimeerde bestand geplakt worden voor het decomprimeren, of kunnen we het algoritme zo schrijven dat dat niet nodig is?
- Stel dat we geen legenda in ons gecomprimeerde bestand willen doen, hoe kunnen we dan verwijzen naar een eerder voorgekomen reeks van tekens, zonder extra tekens toe te voegen?
- Wat is eigenlijk het maximaal haalbare compressie-niveau? Is het mogelijk om elk stuk tekst dat uit willekeurige getypte tekens bestaat op te slaan als een nieuw bestand dat slechts 5% van de grootte heeft van het origineel of kun je een compressie-algoritme "problemen" geven door expres geen herhaling/patronen te laten voorkomen in je tekst?

Diep in gedachten over de vragen die spelen bij compressie
Uitwerken en testen
We gingen brainstormen over een stappenplan. Vervolgens hebben we eerst een zin van ongeveer tien tekens genomen en het hele stappenplan uitgevoerd, met de hand (eigenlijk in Notepad), voor die ene zin. Tijdens het uitschrijven van de werking van het stappenplan voor die ene zin, kregen we ideeën voor verbeteringen. We verbaasden ons erover hoe zinvol het was om het stappenplan stap voor stap, met tussenresultaten, in Notepad uit te schrijven. Dat was ook een fijne manier om ideeën met elkaar te delen: laat maar heel precies zien hoe het idee werkt. Natuurlijk bedachten we nieuwe voorbeeldzinnen waarvan we zeiden: "dit zou ons algoritme met ongeveer 50% kleiner moeten kunnen maken". Toen we het eens waren over een stappenplan, schreven we unit tests en gingen we programmeren. Aan het einde van de ochtend hadden we het eerste plan weer weggegooid en besloten we een andere richting in te slaan.

Twijfels en zekerheden
Gedurende de dag waren er ups ("joepie, 50% compressie werkt!") en downs ("het is toch geen goed idee, want..."). We wisten van tevoren wel dat we niet in een dagje een algoritme konden maken dat vergelijkbaar zou zijn met een populair algoritme... dit wekte juist extra nieuwsgierigheid: welke trucjes zijn daarvoor bedacht? Wat zien we over het hoofd? We wilden het zelf bedenken.
Dagen later
Pas dagen later hebben we meer informatie opgezocht over enkele bestaande algoritmes. Wat we toen leerden was geweldig, slim, simpel, geniaal. Hadden we dat zelf kunnen bedenken? Nu lukte het niet, maar misschien vinden we de komende jaren wel iets anders uit van vergelijkbare waarde 😉
Aanrader
Een compressie-algoritme maken, of een hashing-algoritme maken, of een vergelijkbare logische puzzel doen: dat is echt een aanrader!
Publicatie en video
Het compressie-project en de vele andere hackathonprojecten komen uitgebreid aan bod in onze hackathon aftermovie:
Je kunt de aftermovie van de hackathon hier bekijken!
Benieuwd naar de andere projecten van de hackathon? Lees dan onze publicatie over deze hackathon, en hou ons techblog de komende weken in de gaten.

