Je hebt de termen MCP server en tool use misschien al eens voorbij zien komen, en dat is niet zo gek, want in de afgelopen maanden is er een explosie geweest in het bouwen en gebruiken van MCP-servers. Ook bij Webenable zijn we hier enthousiast mee aan het experimenteren. We zijn zelfs van plan om binnenkort een blogserie te starten waarin we deze concepten uitgebreid gaan verkennen. Maar voordat we het serieus gaan aanpakken… eerst even een kort verhaaltje over een van mijn eigen experimenten die bijna uit de hand liep.
Mijn eerste experiment was simpel: ik wilde mijn lokaal draaiende LLM gebruiken om taken toe te voegen aan mijn Todoist-lijst. Dus ik bouwde een LLM die als standaard prompt-instructies had om ieder bericht te 'vertalen' naar een todoist-taak. Dat zou bijvoorbeeld zo werken:

Voor de geïnteresseerden, mijn lokale setup is als volgt:
- Cherry Studio als chat-applicatie
- LM Studio als LLM provider, waarin verschillende modellen staan
- Een Nvidia GeForce RTX 5090 waar de modellen op draaien
Ik probeerde hiervoor het nieuwe DeepSeek model (deepseek-r1-0528-qwen3-8b). In mijn vorige artikel gaf ik al aan dat ik dit model nog wilde inzetten voor taken waar het beter tot zijn recht komt dan bij vertalingen. En deze use-case leek mij daarvoor uiterst geschikt, want dit model is namelijk een tool-using model. Een tool-use model is geschikt voor tool-calling - de feature die we nodig hebben voor het gebruik van MCP servers.
Het is daarnaast ook een thinking (of reasoning) model. In theorie zou dit een gouden combinatie kunnen zijn, waarbij de reasoning de kans verhoogt om de juiste tool te gebruiken. Maar... we hebben ook gezien dat een thinking model soms door kan slaan in hun reasoning. We zagen in eerdere blog-artikelen al dat ze heel lang na kunnen blijven denken, en zichzelf in twijfel blijven brengen. Zelfs bij vragen zoals 1+1, zoals te lezen was in dit artikel.
Ik gaf mijn LLM een prompt met de instructies om ieder bericht om te zetten naar een task in todoist. Het enige wat nu nog nodig was: een tekst om dit mee te testen. Dat werd: 'make dinner'. De hoop was dat het versturen van dit bericht naar de LLM zou resulteren in dit bericht in mijn taken-lijstje.
Het begon veelbelovend: Ik stuurde het bericht, en hoorde mijn videokaart al direct flink geluid maken. Vervolgens zag ik een lading tekst voorbij streamen, met daarin een mooie notification dat er een todoist task was geplaatst

Succes!
Maar, nee, wacht. Ik zag meer tekst verschijnen. Blijkbaar was de LLM nog, of alweer, aan het denken? En de todoist_create_task completed verscheen nog een keer. En daarna nog een keer!

Ik keek op mijn andere scherm, waar ik mijn lijst langzaam gevuld zag worden.
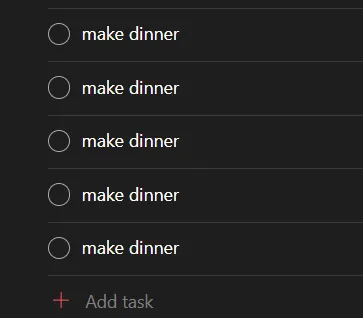
Ik stopte snel de uitvoering van de LLM, want zoveel honger had ik nou ook weer niet.
Wat zou hier aan de hand zijn? Ik ging natuurlijk op onderzoek uit. Ik had al direct enkele hypotheses natuurlijk.
Debugging
Tijd om wat hypotheses te testen. Ik begon met debugging.
Ligt dit aan het gekozen model?
Ik probeerde qwen3-14b, en daar ging het wel goed.
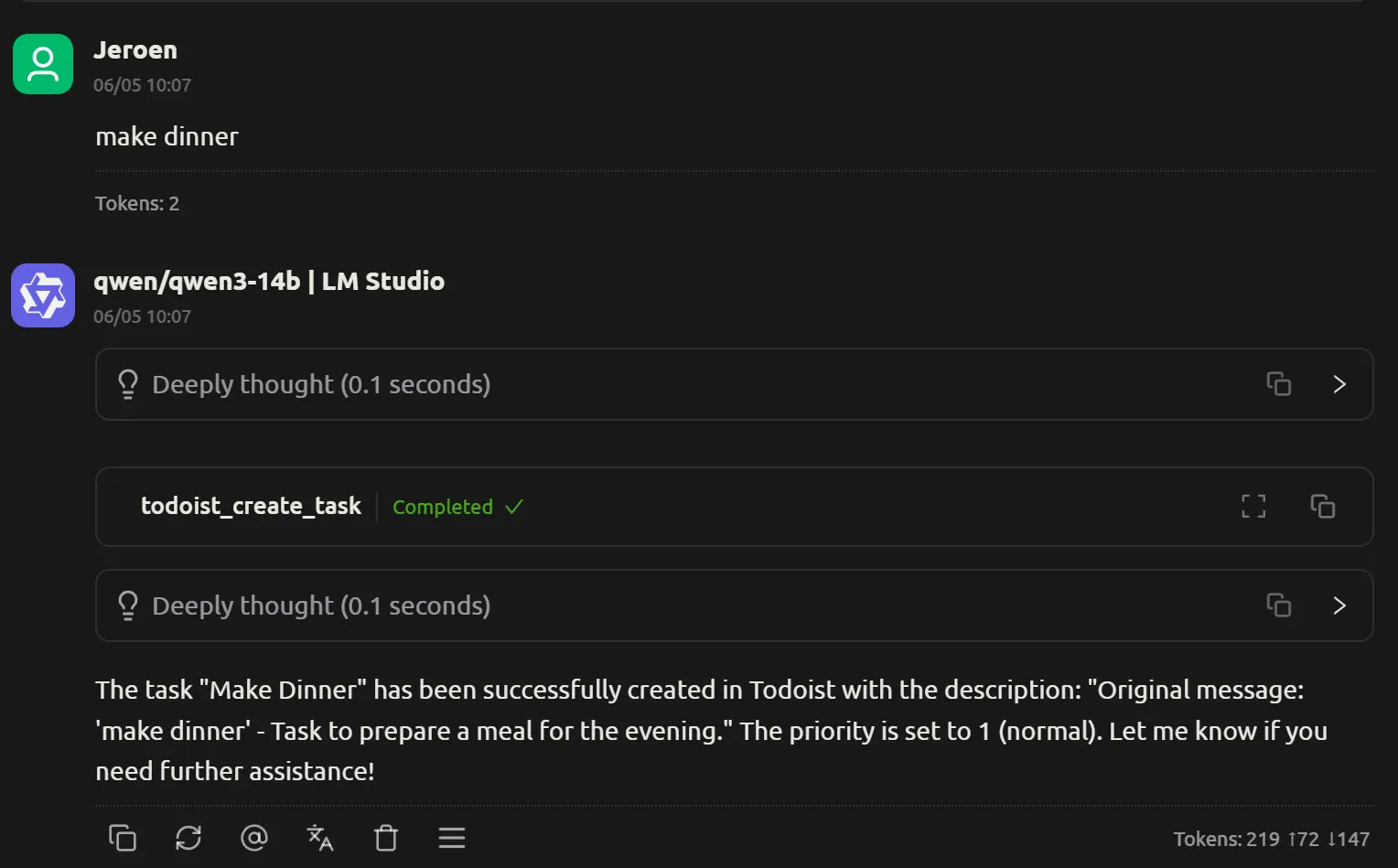
Het viel mij ook op dat de reasoning hier netjes in een uitklapbare box stonden, terwijl de deepseek berichten de thinking en normale output als 1 geheel leek te sturen.
Is er een issue met de reasoning implementatie?
Dit model leek ook de /no_think niet goed te begrijpen. Deze tag wordt (onder water) toegevoegd door mijn chat-applicatie (Cherry Studio), en misschien is deze niet helemaal compatible met dit model? Want deepseek-r1-0528-qwen-3b leek niet te begrijpen wat ermee bedoeld werd.
Bij het qwen3-14B model stond oorspronkelijk de reasoning uit (het resultaat van de /no_think tag), maar ook met de reasoning aan ging het goed.
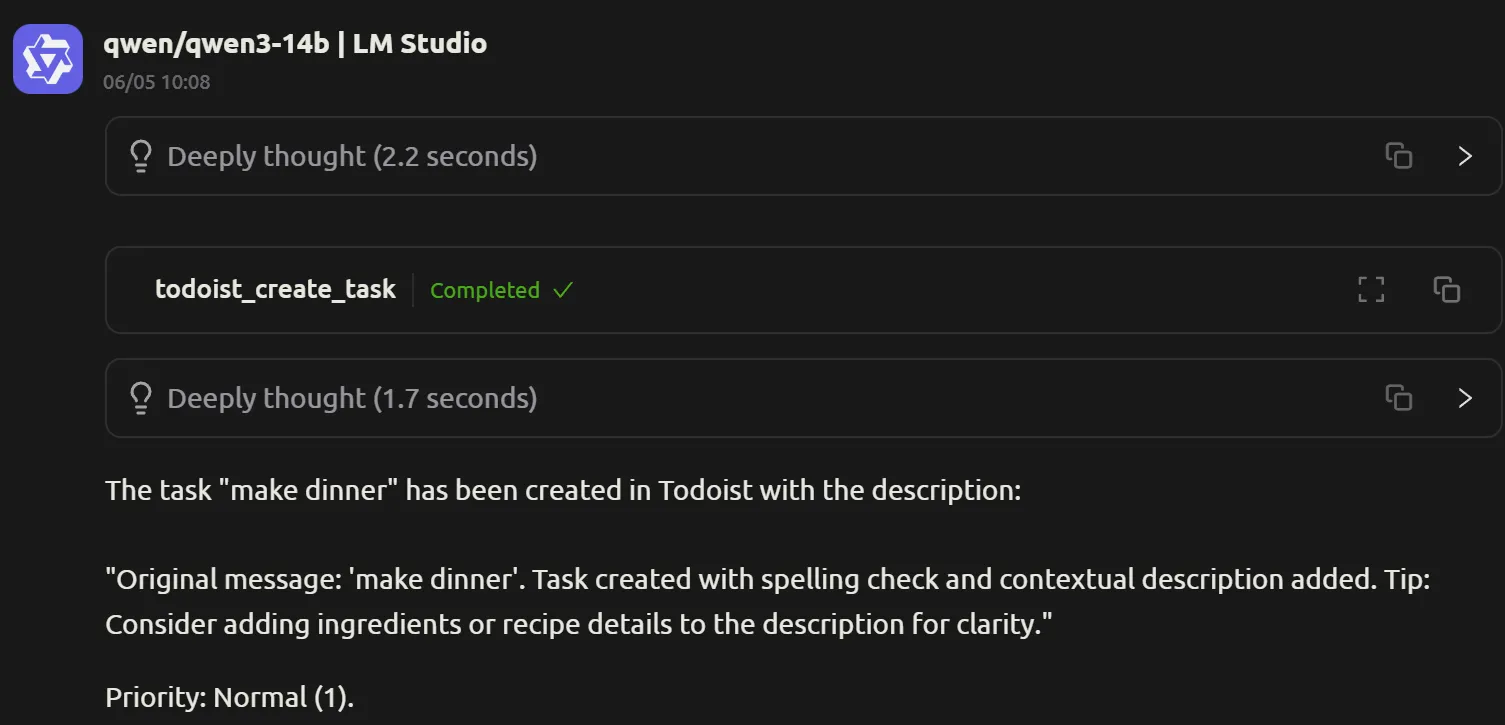
Is deze LLM gewoon niet 'slim' genoeg?
Termen zoals slim en dom zijn niet echt de juiste manier om dit concept uit te drukken, maar bij gebrek aan betere vocabulaire gebruik ik ze toch maar. In mijn blogserie Taalmodellen in actie schrijf ik hier uitgebreider over, maar in het kort: Afhankelijk van hoe en waarop ze getraind zijn kunnen LLMs op sommige vlakken sterker of zwakker zijn. Het kiezen van de juiste LLM die goed bij een bepaalde taak past is dus belangrijk. Maar naarmate een LLM groter wordt (dus meer parameters krijgt) observeren we vaak wel een stijgende lijn in het 'begrijpen' en lijken ze hierdoor 'slimmer'. Zelfs modellen die niet per se geschikt zijn voor een taak kunnen deze, naarmate ze groter worden, vaak toch beter verwerken.
In het spectrum van model-groottes bevindt ons model zich meer aan de kleine kant. Ondanks dat weet het erg knap te presteren, maar modellen die rond dezelfde datum zijn uitgebracht en groter zijn presteren waarschijnlijk nog wel beter.
System prompt filosofie
Bij mijn eerste 'make dinner' poging leek de LLM in een soort oneindige loop te komen, waarbij het (schijnbaar) oneindig lang dezelfde taak bleef toevoegen. Ik heb sindsdien deze situatie niet meer weten te reproduceren - meestal voegde het model dezelfde taak 2, 3 of 4 keer toe, en stopt het daarna op een gegeven moment. Waarschijnlijk als ik mijn oorspronkelijke poging door had laten gaan was dit ook wel gebeurd. Maar ik begreep nog steeds niet waarom deze LLM in de eerste plaats zovaak deze taak blijft toevoegen.
Ik bleef als hardnekkige developer natuurlijk doorgaan met debuggen en experimenteren.

Door bovenstaande reasoning begon ik te twijfelen of de LLM wel mijn system prompt goed doorkreeg. Want in de prompt staan duidelijke instructies, en hier geeft de LLM aan dat hij het behoorlijk vaag vind. Hoe kom ik erachter of de LLM de prompt wel goed doorgegeven krijgt?
Door het te vragen natuurlijk!
Ik was natuurlijk even vergeten dat de prompt instructies zijn: maak van ieder bericht een taak aan. Dus ook mijn vraag 'what is your prompt?' triggerde dit natuurlijk: dit werd omgezet in een taak voor mijn todo-lijstje.
Maar niet alleen dat: want met dit bericht leek ik ook eindelijk weer de situatie te pakken te hebben waarbij de LLM eindeloos taken blijft toevoegen! Dit keer besloot ik om het gewoon uit te wachten, in plaats van de LLM stop te zetten. Dit resulteerde uiteindelijk in 9 nieuwe taken in mijn todoist-lijst. Je ziet de taken zelf steeds cryptischer en esoterischer worden.

Maar toen begon het kwartje te vallen.
Want een MCP server geeft na het uitvoeren van een taak een resultaat terug aan de LLM (zodat de LLM dit resultaat weer kan gebruiken voor vervolgacties, indien relevant). Dit zal achter de schermen wel gebeuren in de vorm van een bericht.
Maar mijn prompt instructies zijn om ieder bericht om te zetten naar een taak. Een todoist_create_task completed bericht is OOK een bericht. Dus daar moet een taak van gemaakt worden! Ieder bericht moet immers omgezet worden in een todoist taak.
Waarom deed qwen3-14B dit niet? Dit model is met 14B bijna 2 keer zo groot als de deepseek 8B. Misschien was het daardoor 'slim' (daar is dat woord weer) genoeg om te beseffen dat dit bericht van een MCP server kwam? Ditzelfde fenomeen kwamen we in eerdere blog-artikelen ook al tegen, waar we bijvoorbeeld zagen dat een LLM soms een taak wel uit kon voeren, maar niet 'slim' genoeg was om de prompt te begrijpen. En we hebben in deze vorige blog-artikelen ook gezien hoe we de responses van kleinere modellen kunnen verbeteren: door beter passende prompts te maken!
Maar dat is een onderzoek voor een andere keer. Voorlopig ben ik overgestapt op andere modellen voor deze taak. Qwen3-14B doet het al een stuk beter, al ontstaan daar soms ook situaties waarin requests fout blijven gaan. Qwen3-32B en Gemma3-27B zijn tot nu toe foutloos geweest, maar deze modellen zijn zo groot dat ze maar net op mijn videokaart passen, zolang ik niet teveel andere applicaties heb draaien op mijn computer.
En nu ga ik maar eens aan die 'make dinner' taak beginnen.

