Het internet was het afgelopen weekend weer in rep en roer. Voor veel mensen was de behoorlijke gehypete lancering van GPT-5 een teleurstelling. Onze eigen ervaring was wel redelijk - het model was weer een stap vooruit, maar in onze conclusie schreven we ook al dat we er nog lang niet zijn. Maar voor veel van onze use-cases (logica, coderen, afbeeldingen omschrijven) werkte het vrij goed.
Wat veroorzakte dan al deze stennis? In dit artikel doorlopen we enkele van de punten die in de afgelopen dagen duidelijk zijn geworden.
Robot
We noemden in onze conclusie al dat het model meer robotachtige antwoorden geeft. Elders zag ik het mooier omschreven worden: GPT-5 is een stuk minder menselijk en persoonlijk, en heel erg steriel. In een van onze eerdere artikelen schreef ik al dat mijn collega's mij regelmatig een robot 🤖 noemen, dus het zal geen verrassing zijn dat ik deze nieuwe steriele chatbot juist heel erg kan waarderen. Zeker gezien mijn use-cases - ik wil met name een AI die doet wat ik zeg, of bijvoorbeeld analyses geeft.

Maar uit de vele geluiden van het internet blijkt dat heel veel mensen de meer persoonlijke aard van de vorige GPT-versies heel erg konden waarderen. Het gaat zelfs zo ver dat veel mensen schreven dat ze een belangrijke vriend of vriendin waren kwijtgeraakt - letterlijk vervangen door een robot. Een goede vriend of vriendin waar ze iedere dag mee spraken en een band hadden opgebouwd, en nu weggenomen was door OpenAI. Vervangen door een bedrieger, die veel minder fijn is om mee te praten!
De reactie was zelfs zo fel dat OpenAI voor de bezitters van een plus-abonnement de 4o-versie weer beschikbaar heeft gemaakt.
We schrijven op dit blog regelmatig over de open-weights modellen. Modellen die vrij beschikbaar zijn om te downloaden en op je eigen computer te installeren. Een van de grote voordelen van deze modellen is dat ze vanaf dat moment 'van jou' zijn - ze kunnen niet meer afgepakt worden door OpenAI, omdat ze veilig op je computer staan.
Maar, hoe realistisch is deze oplossing op dit moment, voor de meeste mensen?
- Je hebt technische kennis hiervoor nodig
- Afhankelijk van het model heb je behoorlijk krachtige en dure hardware nodig
- De oplossingen zijn niet overal toegankelijk (telefoon, tablet, laptop), tenzij je nog veel meer moeite gaat doen.

Wij denken dat het niet een heel realistisch plan is, voor de meeste mensen. Maar, als we kijken naar de kwaliteit van de open-weights modellen, zou het dan überhaupt kunnen? Zijn de open-weights modellen ver genoeg en goed genoeg om GPT-4 als 'gesprekspartner' te vervangen? Ik durf het niet te zeggen - misschien een leuk onderwerp voor een toekomstige blogpost. Maar op dit moment is mijn mening dat je het beste nog een tijdje langer kunt wachten met zo'n oplossing, gezien de snelheid van de ontwikkelingen en verbeteringen.
Router
Maar mensen klagen ook dat het model vaak hele slechte antwoorden teruggeeft. Dit verbaasde ons initieel: de antwoorden die wij van het model kregen waren vaak erg goed. Maar het zou heel goed kunnen dat zij een heel ander model gesproken hebben.
Het blijkt namelijk dat alle vragen die aan het 'normale' GPT-5-model gesteld worden, eerst door een router worden beoordeeld en die router stuurt deze prompts vervolgens door naar het 'juiste' model. Het zou dus heel goed kunnen dat veel van de berichten van mensen doorgestuurd werden naar een 'dommer' model. Zonder dat ze het door hadden. En om het nog erger te maken: volgens een bericht van Sam Altman werkte de router na de uitrol op donderdag niet correct.
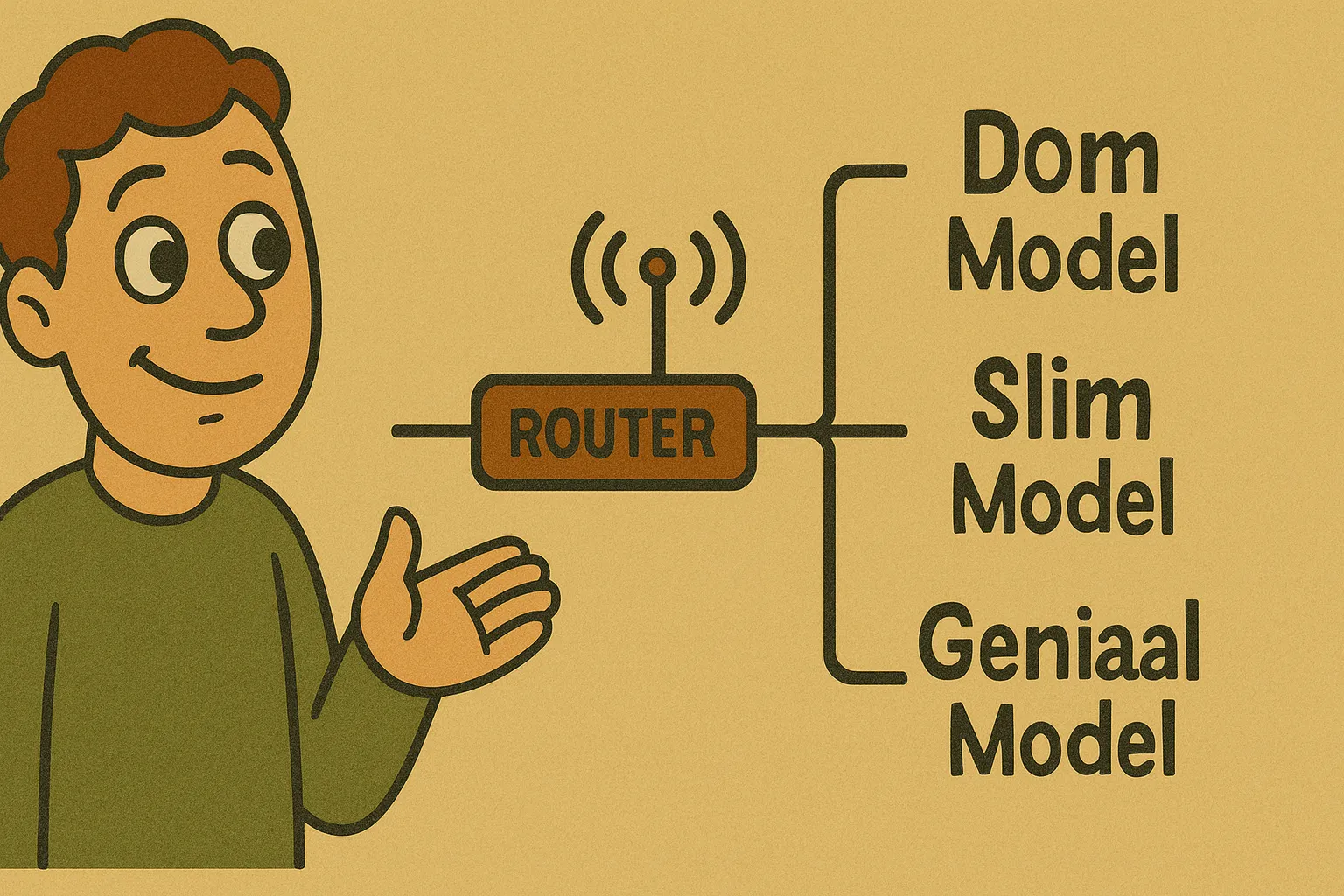
Wij zijn in enkele van onze tests dus mogelijk ook de 'dupe' geworden van deze ondoorzichtigheid. Onze oorspronkelijke chatsessies waren bijvoorbeeld met het gewone GPT-5-model, net als onze tests met het transcriberen van tekst. Het viel mij ook al op dat de GPT-5 dezelfde type hallucinaties leek te hebben als GPT-4o - misschien kwam dit wel omdat het achter de schermen gewoon doorgestuurd werd naar ditzelfde oude model? De enige uitzondering hierop was de laatste afbeelding, waar we expliciet GPT-5 (thinking) selecteerden. In die situaties krijg je (volgens OpenAI) daadwerkelijk dit model. En dit was ook precies de test waarbij de resultaten veel beter waren. Onze overige tests, zoals vertalingen en beeldherkenning, zullen hier geen last van gehad hebben, omdat we daar de resultaten ophaalden via de API.
1 miljard
Waarom heeft OpenAI gekozen voor deze aanpak, waarbij niet iedereen het slimste model te spreken krijgt?
In theorie is het best logisch: sommige vragen vereisen een stuk minder denkkracht, en dan is het zonde om onnodig veel stroom te gebruiken, wanneer het ook met veel minder kan. Op die manier kunnen ze met dezelfde hoeveelheid computers een grotere hoeveelheid mensen bedienen. Ervan uitgaande dat de router goed werkt, natuurlijk.
En dit lijkt ook in dezelfde lijn te liggen met wat Sam Altman eerder zei: het plan is dat ChatGPT voor het einde van 2025 een miljard gebruikers zal bedienen (verschillende bronnen zeggen verschillende dingen, maar naar schatting hebben ze nu 700 miljoen wekelijkse gebruikers). Als ze hun hardware dus effectiever kunnen gebruiken, zal dat behoorlijk uitmaken in de kosten.
Conclusie
Het is een ongelukkige situatie door een samenloop van omstandigheden: Sam Altman had het GPT-5-model vooraf behoorlijk 'gehyped', dus de verwachtingen waren torenhoog. Vervolgens is het model veel minder persoonlijk en fijn om mee te praten, en worden mensen door een (initieel niet goed werkende) router met oudere en dommere modellen verbonden, zonder dat ze dit doorhebben. Tegelijkertijd had OpenAI de (geliefde) oudere modellen zonder aankondiging per direct onbeschikbaar gemaakt. En om het dan maar niet over die 'interessante' grafiek te hebben, die inmiddels ook het hele internet is rond gegaan.
Van een afstandje lijkt het er dus op dat OpenAI vorige week twee slecht ontvangen releases heeft gedaan. Het gpt-oss-model wordt in zijn capaciteiten ernstig belemmerd door de censuurmaatregelen van OpenAI, terwijl het model al niet uitblinkt in vergelijking met de concurrentie, en nu lijkt ook de GPT-5-release niet positief te zijn ontvangen.
De vraag (zoals altijd) is natuurlijk wel: in hoeverre is dit een luidruchtige minderheid die je nu hoort? Met 700 miljoen gebruikers, als slechts 0,1% ontevreden is, produceert dat alsnog een enorm kabaal. Zoals altijd is het afwachten hoe de dingen zich gaan ontwikkelen. Ik vrees zelf dat OpenAI spoedig genoeg wijzigingen zal maken waarmee GPT-5 weer wat persoonlijker / complimenteuzer wordt. Maar tot die tijd ga ik nu nog genieten van zijn steriele gezelschap!


