Er is een nieuw model uitgebracht in de Gemma 3n-serie. Iets minder dan twee maanden geleden schreven wij al over deze nieuwe reeks van modellen van Google in ons artikel over Gemma 3n. In dat artikel hebben wij de 2B- en 4B-modellen bekeken. Voor meer informatie raden wij aan om dit artikel te lezen, maar de korte conclusie was dat het een indrukwekkend model is, gezien het formaat.
Trouwe lezers van dit blog weten dat ik een voorliefde heb voor kleine modellen. Ik was dus zeer enthousiast toen ik las dit nieuwe Gemma 3n-model extreem klein was! Met slechts 270M parameters is dit het kleinste model dat wij ooit in dit blog hebben besproken. Hoe kleiner een model, hoe 'dommer' een LLM is. Ik ben heel erg benieuwd wat ze kunnen bereiken met een model dat zo ongelooflijk klein is.
Dus laten we beginnen met onze gebruikelijke kennismakingsconversatie met de LLM.
Kennismaking
Vergeleken met de vele andere modellen waar we deze conversatie mee gehad hebben, zien we al direct dat dit model een stuk zwakker lijkt. Het lijkt niet echt antwoord te geven op onze vraag, maar meer tekst te genereren die gerelateerd is aan de inhoud van mijn bericht.
Maar laten we niet vergeten dat dit in het Nederlands was. Het is al heel bijzonder dat modellen van dit formaat überhaupt Nederlands redelijk lijken te begrijpen en spreken. In het Engels zullen ze een stuk sterker zijn.
Deze conversatie leek al iets meer op een echt gesprek, maar tegelijkertijd kreeg ik het idee dat we toch wat langs elkaar heen praatten. Vooral in het tweede bericht krijg ik de indruk dat de LLM denkt dat ík een LLM ben. Het is wat eigenaardig 🤔. Zou het kunnen dat het model misschien hier niet voor bedoeld is? En ook vreemd, het model staat ook nog niet op OpenRouter, dus ik kan het ook nog niet aanroepen via de API. Zouden deze dingen met elkaar te maken kunnen hebben?
Fact sheet
- Open weights
- 270M parameters
- 32k context window
- Goed in het volgen van instructies (relatief gezien aan het formaat)
- Extreem energiezuinig
Use case
We benoemen dit wel vaker in ons blog, en waarschijnlijk werd het uit de kennismaking ook wel duidelijk: deze LLM lijkt niet een hele goede conversatiepartner te zijn. Maar dat wil niet zeggen dat het een 'slechte LLM' is. Het vergelijken van LLM's wordt altijd moeilijk gemaakt omdat alle LLM's sterktes en zwaktes hebben op verschillende gebieden, en de kunst dus is om de juiste LLM voor de juiste taak in te zetten.
En voor welke taak is dit model bedoeld? Dit model is niet zozeer out-of-the-box geschikt voor bepaalde dingen, en is ook niet bedoeld om direct gebruikt te worden. Dit model is juist bedoeld als basis, om gefinetuned te worden op specifieke en/of gespecialiseerde taken. Het is dus eigenlijk de 'ultieme' versie van het idee om de juiste LLM in te zetten voor de juiste taak.

The right tool for the right job.
Fine tuning
Wat is fine tuning?
Voordat we die vraag kunnen beantwoorden, is het weer belangrijk om te begrijpen wat een LLM is. Een LLM is een groot neuraal netwerk van parameters (in het geval van Gemma 3n 270m zijn dit dus 270 miljoen parameters), die bepalen hoe input wordt omgezet naar output. De 'waardes' van deze parameters bepalen op welke manier dit gebeurt. Voor meer details raden we aan om onze eerdere blogartikelen te lezen.
In ons artikel Taalmodellen in actie - Deel 2: Waarheid op proef merkten we op hoe het toepassen van de 'few shot'-promptingtechniek de resultaten dramatisch verbeterden. Omdat een LLM meer data (meer tokens) heeft om mee te werken, is het beter om zijn patroonsherkenning toe te passen. Maar bij deze techniek verandert er niks aan de LLM zelf.
Het fine-tunen van een model daarentegen betekent dat je wijzigingen gaat maken aan de waardes van de parameters van de LLM.
Stel dat we de simpelste LLM hebben die we ons voor kunnen stellen. Deze LLM genereert, ongeacht de input, altijd dezelfde output, namelijk het woord: 'kat'.
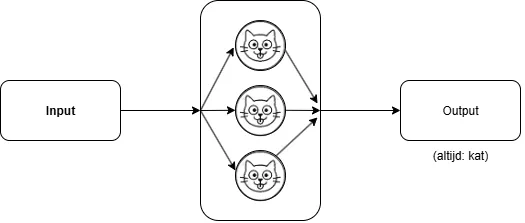
Links de input, in het midden een "LLM", die ieder woord naar kat veranderd, die rechts als output eruit komt
Het is waarschijnlijk de meest nutteloze LLM ooit, maar het gaat hier om het idee. We hebben hier dus een neuraal netwerk, gevuld met parameters, die zo gemaakt zijn dat ze altijd het woord 'kat' genereren. Dus als ik het woord 'aap' stuur naar de LLM, stuur hij 'kat' terug. Idem voor het woord 'vlaflip'; dan krijg ik weer een 'kat' terug.

Nu willen we deze LLM gaan finetunen, om hem wat nuttiger te maken. Het finetunen verandert de daadwerkelijke waardes van de parameters. Ons doel is om de LLM te finetunen zodat hij vanaf nu altijd het woord 'hond' terugstuurt. Dit kunnen we dus doen door de parameters aan te passen.
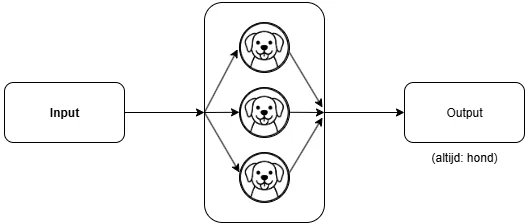
Na finetuning van de LLM door alle parameters te vervangen krijgen we nu alleen nog maar het woord hond eruit, in plaats van kat.
Bovenstaande voorbeeld is natuurlijk een extreme simplificatie (en niet helemaal accuraat, zoals we hieronder uitleggen). En in bovenstaande voorbeeld hebben we álle parameters vervangen - we hadden dus net zo goed een hele nieuwe LLM kunnen maken. Maar meestal wanneer je een LLM gaat finetunen richt je dit proces op specifieke lagen, of specifieke 'paden'. En LLM's die speciaal geschikt zijn voor dit finetuneproces, zouden bijvoorbeeld specifieke lagen of parameters 'leeg' kunnen laten; speciaal bedoeld om tijdens het finetunen te vullen met de gewenste waardes.
Voorbeelden van finetunes
Waar zou je zo'n model als dit allemaal op kunnen finetunen? Zoals gebruikelijk zijn de mogelijkheden vrijwel onbeperkt, maar enkele voorbeelden die wij tegen zijn gekomen:
- Classificatie van sentiment voor productrecensies, app-feedback of supporttickets (positief/neutraal/negatief).
- Genereren van omschrijvingen en teksten van producten, zoals titels, tags en meer.
- Auto-aanvullen van teksten binnen specifieke domeinen.
- Opschonen en ontdubbelen van data.

Waarom finetunen?
Maar, bovenstaande voorbeelden zou je ook allemaal kunnen bereiken met een grotere LLM. Waarom niet gewoon een 8B-model (of bijvoorbeeld zelfs ChatGPT via een API) inzetten dat al deze taken kan doen, in plaats van vier losse modellen te finetunen? Het is namelijk niet eenvoudig om zo'n model te finetunen, daar komt nog heel wat bij kijken.
Hier komen we weer bij een terugkerend thema van ons blog, en eigenlijk ook een terugkerend thema bij software development in het algemeen, namelijk: alles is een afweging. En meestal is die afweging complexiteit tegenover performance (of benodigde resources).
Zo'n 8B-model neemt bijvoorbeeld bijna acht keer zoveel ruimte in beslag als die vier Gemma-modellen samen. In andere woorden: Je kunt of een enkel 8B-model draaien, of (ongeveer) dertig van deze Gemma-modellen. En ook 8B-modellen zijn relatief klein - de echt serieuze modellen kunnen makkelijk tien tot honderd keer zo groot zijn.
Bovendien draaien deze Gemma-modellen over het algemeen ook nog sneller dan de grote modellen. En omdat ze zo klein zijn kunnen ze overal op draaien - telefoons, tablets, laptops, etc. en ook vrij eenvoudig op de CPU (in plaats van op de GPU). Het is hierdoor natuurlijk ook een stuk beter voor het milieu.
Hoe ziet de toekomst eruit?
Dit soort modellen laten wat mij betreft een mogelijke toekomst zien. Een toekomst waarin op de meeste apparaten tientallen of honderden verschillende gespecialiseerde LLM's klaarstaan, om op ieder moment te helpen met het uitvoeren van hun specifieke taak.
En honderden modellen op bijvoorbeeld een telefoon klinkt natuurlijk als best veel. Want dit model is klein, maar honderd keer dit model zou veel meer geheugen vereisen dan de huidige toestellen hebben. Maar vergeet niet: we zitten nog steeds vrij vroeg in de ontwikkelingen van LLM's - en alles technologie eromheen.
Het is goed mogelijk dat op alle vlakken verbeteringen komen - zoals nog kleinere 'foundation'-models, zodat je uiteindelijk misschien per taak een bepaald formaat kunt kiezen om mee te werken. Want we zien ook op dit vlak een trend dat kleine modellen steeds beter worden. En hopelijk wordt ook de technologie rondom het finetunen steeds beter, om ook dit proces makkelijker te maken.
Ik denk in ieder geval dat Google weer een mooi model beschikbaar heeft gemaakt, en ik ben erg benieuwd waar we hiermee over enkele jaren zullen staan.


