
Nieuwsgierig wat hier gebeurt? Lees dan verder.
In ons artikel Wat wij vinden van Veo 3 maakten we kennis met deze video-generator van Google, en vergeleken we deze ook kort met Sora, de video-generator van OpenAI. Mijn conclusie was dat Veo 3 behoorlijk indrukwekkend was, ondanks dat-ie soms nog wat gekke dingen deed. En de toevoeging van geluid bij video's had, wat mij betreft, echt heel veel toegevoegde waarde. Sora daarentegen had geen geluid, en de videobeelden leken (bij mijn prompts) vooral op koortsdromen.
Eind juli kwam Wan 2.2 uit. Een video generation model, geproduceerd door het Chinese bedrijf Alibaba. En zoals met veel releases van deze Chinese modellen, is dit een open model. Waar de modellen van Google (Veo 3) en OpenAI (Sora) 'geheim' zijn, is dit juist een model wat je kunt downloaden en installeren op je eigen computer. Sinds de release van Wan 2.2 kom ik regelmatig geluiden tegen over hoe goed dit model is. Sommige beweren dat het zelfs beter is dan veo3!
Een open model dat beter is dan Veo 3? Dat zou waanzinnig zijn! In dit blogartikel gaan we het vergelijken met enkele video's die we al eerder gegenereerd hebben in ons artikel over Veo 3.
Over Wan 2.2
Wan 2.2 is de opvolger van Wan 2.1 (die als voorgangers Wan 2.0 en Wan 1.0 had). Ten opzichte van Wan 2.1 is het een grote upgrade, met verbeteringen op allerlei vlakken, waaronder de architectuur, een veel grotere hoeveelheid trainingsdata en het model is veel beter in het volgen van instructies.
Wan 2.2 is een multimodal video generation model. Dat wil zeggen dat het in staat is om tekst om te zetten naar video, maar ook afbeeldingen naar video.
Het is een MoE (mixture of experts) model, waarbij het twee modellen heeft. Een high-noise expert voor de eerste 'stappen' van de generatie, en een low-noise expert die in de latere stappen toegepast wordt en verantwoordelijk is voor de details.
Er zijn 3 modelvariaties: T2V-A14B, I2V-A14B en TI2V-5B.

Deze namen klinken complex, maar dat valt heel erg mee
T2V-A14B
Dit model is een text-to-video (T2V) model. Het ondersteunt dus geen afbeeldingen. Het tweede deel geeft aan dat het de A-serie is, met (ongeveer) 14 miljard actieve parameters per expert (en dus 27 miljard in totaal). Dit model vereist ongeveer 80GB aan VRAM (of normaal RAM, maar dan wordt hij een stuk minder snel).
I2V-A14B
Dit model is vergelijkbaar, alleen begint het met de letter I in plaats van de letter T, waarbij de T voor text staat, en de I voor image. Dit is dus het image-to-video model, maar verder identiek (ook MoE en 80GB VRAM vereiste).
TI2V-5B
Dit is het kleinere model, geschikt voor de GPU's die je in 'consumentencomputers' kan vinden, en dan met name de videokaarten die door de echte game-enthousiastelingen worden gebruikt, zoals de NVIDIA 3090, 4090 en 5090 kaarten. Het model, met 5 miljard parameters, vereist namelijk alsnog 24GB VRAM, en dat hebben de meeste kaarten niet. Daarnaast is het, in tegenstelling tot de andere twee modellen, geen MoE-model.
Als je dit model dus lokaal wilt draaien, zou je denken dat je de TI2V-5B moet hebben. Maar dat is dus niet zo: kort nadat Wan 2.2 werd uitgebracht, zijn er van de A14B versies al 'lower quants'-versies gemaakt. En deze versies draaien dus óók op consumenten-GPU's, en lijken in praktijk beter te werken dan de 5B-versie!
De balkendraak
Trouwe lezers van dit blog zijn inmiddels goed bekend met de balkendraak. Veo3 wist deze best aardig te animeren - Wat levert Wan 2.2 hierbij op?
Balkendraak in bewegingVideo
while a person in a green shirt is watching him with a wondering expression.
Een leuke animatie, en de reactie van het rechter-personage is ook wel erg gepast. Ik vind deze animaties eigenlijk nog wel een stuk beter dan die van Veo 3! Alleen... het heeft natuurlijk totaal niet mijn instructies opgevolgd. Dus een interessant begin!
De fotograap
Zowel Veo 3 als Sora waren bij de fotograap slecht in het volgen van de prompts. Al waren de video's die ze produceerden wel behoorlijk grappig.
De fotograapVideo
Ook Wan 2.2 weet hier iets bijzonders te produceren... Maar we hadden tee prompts hiervoor, hoe doet hij met de andere?
De fotograap, met ander promptVideo
Waarom opeens twee gorilla's? Ik denk dat hij in de instructies het cijfer 2 voorbij zag komen. En geen enkele camera in zicht. Het was dus weer totaal niet waar ik om vroeg, maar wel echt leuk. Ik vind vooral het einde van de video erg komisch, want het lijkt net alsof die ene gorilla nog terug komt, omdat-ie nog niet helemaal klaar was met Henk!
Waarom moeten ze eigenlijk iedere keer Henk hebben? Arme Henk.
Bungeejumpen - althans, dat was de bedoeling
Jeroen, stop met die flauwe grappen! Dit kost ons een fortuin!Video
Deze vergelijking is wat minder nuttig natuurlijk - Veo 3 genereert audio, en een groot deel van deze prompt was daarop gebaseerd. En het was natuurlijk ook als commentaar bedoeld op de prijs van Veo 3. Wan 2.2 is in vergelijking een stuk goedkoper. Dus de hele video is eigenlijk niet relevant.
Toch zijn hier enkele interessante punten: Net als de Veo 3-variant, is deze video puur op basis van tekst gegenereerd - er was dus geen referentieafbeelding. En ook hier zien we dat het volgen van instructies niet helemaal goed gaat, want, ondanks dat ik hier totaal geen expert in ben, denk ik niet dat dit een bungeejump is. Maar ach, bij de Veo 3-variant sprong Jeroen immers ook zonder bungeetouw naar beneden.
Wat is Len op het spoor?
Enige tijd geleden gingen wij met het team naar de Efteling. Heb je hiervan onze blogpost en video al gezien? Toen onze collega Len oog in oog kwam met deze onweerstaanbare stoomtrein was het liefde op het eerste gezicht. We hebben hem daarna de rest van de dag niet meer teruggezien (je zou kunnen zeggen dat hij... spoorloos... was). Rond sluitingstijd haalden we hem weer op, en met veel tegenzin kwam hij weer mee.
Toen ik in juni die foto zag, was het eerste wat ik dacht: die moeten we via een AI-video laten rijden! Maar, de kosten van het genereren daarvan (in Veo 3) kwam al snel neer op 6 tot 10 euro per video. En soms gaan ze wel eens 'fout', en moet je er een paar genereren. Hoe graag ik Len ook zou willen zien rijden in die trein, ik kon het niet rechtvaardigen om daar 30 euro voor te betalen.
Maar Wan 2.2 draaien is een stuk goedkoper! Dus zou ik hiermee, na al die tijd, wel mijn wens kunnen vervullen? De eerste paar pogingen zagen er niet heel hoopvol uit.
Len Trein 1Video
Deze video generators produceren altijd extrapolaties van gezichten van mensen, die vaak niet helemaal overeenkomen met de werkelijkheid. En het persoon die daar uit de trein stapt is ook een stuk forser dan onze eigen Len. En dan is er ook nog de goocheltruc die Len uithaalt, waarbij hij weer verschijnt in de trein. Misschien ergens een verborgen luik?
Maar, ondanks de vele pogingen, bleek de trein koppig statisch. Er was echt geen beweging in te krijgen. Ook hier kreeg ik meer het idee dat het volgen van de instructies van mijn prompt niet goed ging. Maar, na nog meer pogingen, zat er opeens een video tussen waar mijn wens toch in vervulling kwam! De trein begon te rijden!
Len in locomotieVideo
Helaas had ik hier de resolutie op 480 x 480 gezet, dus daarom is het formaat nogal vreemd. En de video is helaas eigenlijk ook net te kort, de actie begint net, en de video is alweer voorbij. Maar toch, het was een rijdende trein! Hoe komt het eigenlijk dat deze video opeens zo'n vreemd (vierkant) formaat heeft? Dat komt omdat dit 1 van mijn eerste pogingen met ComfyUI was.
ComfyUI
Misschien merkte je het al in de video's hierboven: er zit wat variatie in de uitvoering (kwaliteit en resolutie) van deze video's. Dat komt omdat ik deze video's op verschillende manieren heb geproduceerd. Ik begon met het gebruiken van een dienst en een API, maar Wan 2.2 is een open model. Een open model houdt in dat je het vrij kunt downloaden en installeren op je eigen computer. Maar het feit dat iets 'kan' wil natuurlijk niet zeggen dat het ook daadwerkelijk praktisch is om te doen. Dus om dit uit te zoeken, ging ik hiermee aan de slag.
Om lokaal image en video generation models te kunnen draaien heb je software nodig waarin je workflows kunt configureren waarin deze modellen geladen en gebruikt kunnen worden. Er zijn verschillende mogelijkheden, maar een van de meest populaire opties is ComfyUI.
ComfyUI is een applicatie waarin je een AI-workflow kunt configureren op basis van nodes. Nodes zijn een visuele manier om processen te bouwen, waarbij je blokken (nodes) via lijnen met elkaar kunt verbinden, waarbij ieder blok een eigen actie is, zoals het inladen van een model, het toepasen van een filter, of het opslaan van een afbeelding. Deze blokken hebben verschillende verbinden, waarmee je bijvoorbeeld de 'output' van het ingeladen model door kunt sturen naar de 'input' van een sampler.
Voor Len en zijn trein, kwam dat er als volgt uit te zien:
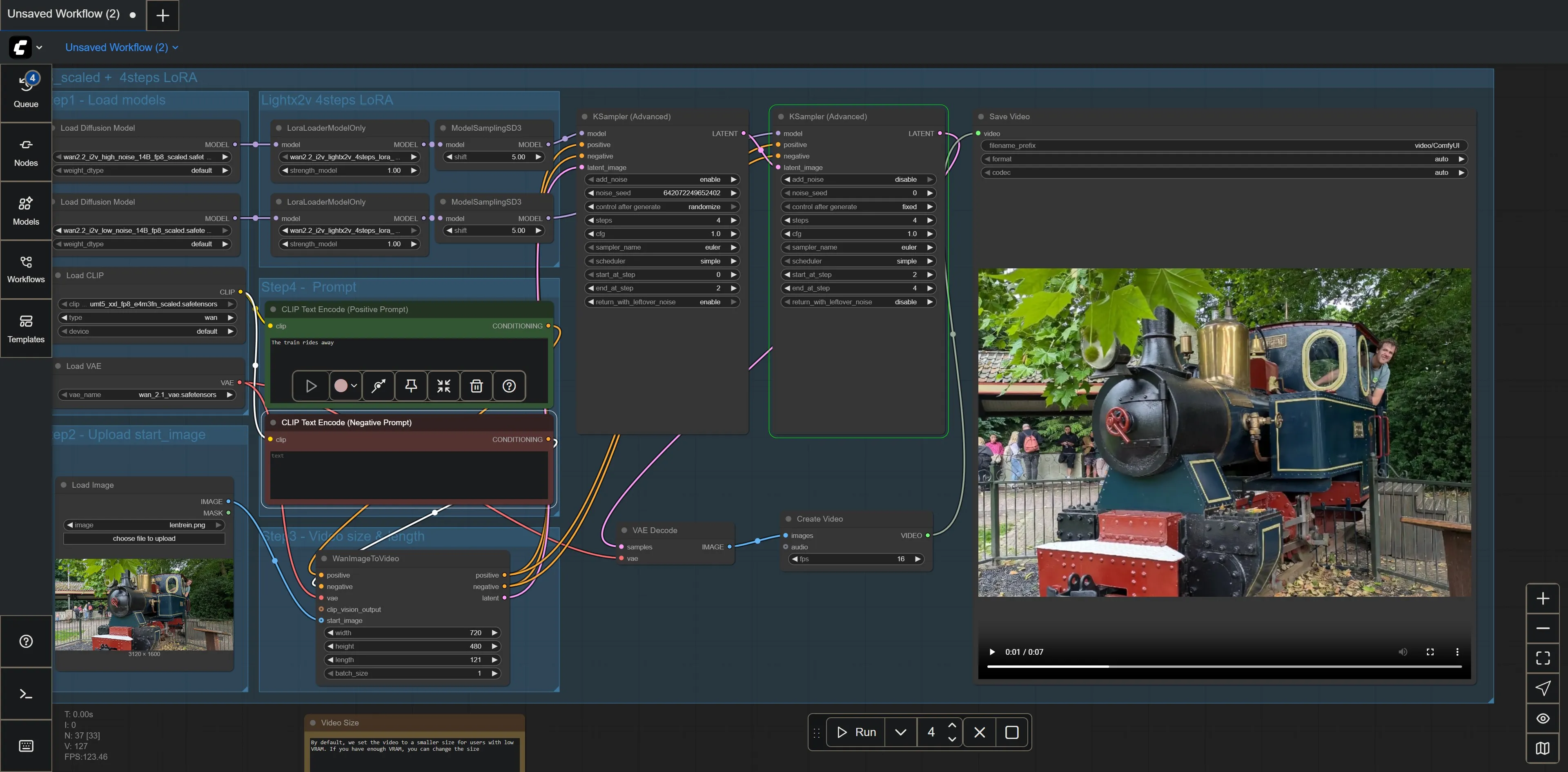
Het overstappen van het gebruiken van een dienst naar ComfyUI is een behoorlijke transitie. Alle complexiteit en details die eerst verborgen was, wordt nu opeens zichtbaar.
Toch viel het mee. Bovenstaande configuratie ziet er complex uit, maar is gebaseerd op een van de beschikbare Wan 2.2-templates. Het was dus grotendeels een kwestie van de nodige diffusion models, lora models en meer downloaden en in de juiste directory zetten, en wat sleutelen met enkele van de instellingen, zoals het aantal frames, de resolutie, de referentie-afbeelding en het prompt.
Daarna was het slechts een kwestie van op Run klikken, en toeschouwen hoe mijn computer langzaam het geluid van een opstijgende straaljager begon te produceren. Maar, na 60 seconden, had ik mijn lokaal geproduceerde video!
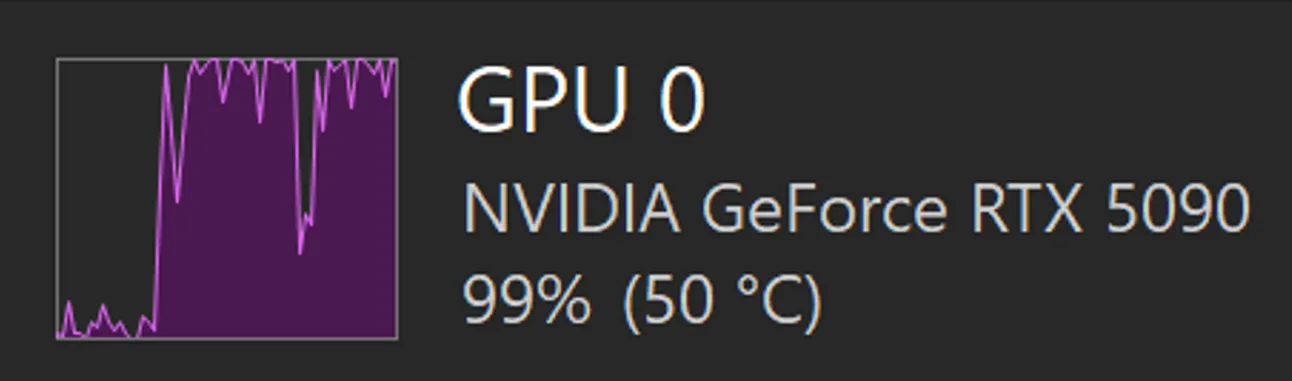
Er zit een zichtbaar dal tussen de pieken. Ik denk dat dat het moment was waarop er gewisseld werd tussen de 2 experts - dus van de high-noise expert naar de low-noise. Deze moeten eerst weer ingeladen worden in het geheugen (VRAM), voordat de videokaart weer verder kan gaan met het uitvoeren van de daadwerkelijke taak.
Maar, in hoeverre is het nu realistisch om dit lokaal te draaien? Ik heb een vrij forse (en dure) videokaart (een NVIDIA 5090) in mijn computer zitten, en ondanks dat gebruik ik in de bovenstaande configuratie de 'quantized' versies van de modellen (de low en high noise experts). Er moet dus een aardige compromis gesloten worden om tot dit resultaat te komen. Ik denk zelf dat dit nog steeds een early adopter is, maar als we hier dezelfde optimalisaties en vooruitgang in blijven zien, kan dat plaatje (of video) er over een paar jaar heel anders uitzien!
Een soft max van 5 seconden
Officiëel ondersteunt het model video's (of clips) van 5 seconden - want dit is waar het met name op getraind is. Het is mogelijk om de configuratie aan te passen zodat hij langere clips genereert. je leest op fora wel dat het model vrij snel slechter begint te werken: de kwaliteit gaat omlaag en fragmenten beginnen zich te herhalen.
En dat zagen wij natuurlijk ook terug! Zowel bij de gorilla die nogmaals terug naar Henk kwam, als bij de video van Len die opeens weer in de trein verschijnt.
Harry Potter-kranteffect
Nu ik eenmaal lokaal deze setup heb, is de 'barrière' tot het genereren van willekeurige afbeeldingen een stuk lager. De kosten van het genereren van een Veo 3-afbeelding waren 6 euro per stuk, dus daar was ik vrij terughoudend in. De kosten van een Wan 2.2-afbeelding liggen online rond de 10 tot 30 cent. Maar lokaal kost het niks! Behalve de stroomkosten en slijtage van je videokaart natuurlijk (en natuurlijk uberhaupt de eenmalige aanschaf van de apparatuur).
Dus opeens heb ik nu de optie om iedere willekeurige afbeelding 'tot leven' te brengen. Puur toevallig stuurde iemand mij die dag een kranten-artikel. En dat leverde echt een bijzonder resultaat op, omdat het gelijk laat zien hoe bijna magisch dit kan zijn. Onderstaande voorbeeld is niet het artikel wat ik opgestuurd kreeg, maar eentje die een stuk minder privacy-gevoelig is. Hopelijk is dit voorbeeld alsnog leuk voor de Harry Potter-fans onder ons, die zich de bewegende krantbeelden nog herinneren.
Eerst de oorspronkelijke afbeelding:

Wow! Schaken tegen de computer! Oh, en iets over een koningin.
Wat voor video kan Wan 2.2 hiervan maken?
Schaken tegen de computerVideo
Conclusie
Om maar gelijk met de deur in huis te vallen: Wan 2.2 is niet beter dan Veo 3. Het is minder goed in het volgen van instructies, en persoonlijk vind ik het ook jammer dat de video's geen geluid produceren (maar afhankelijk van je use-case, is dit helemaal geen nadeel - ik kan me best voorstellen dat sommige power users dit juist niet willen). Daarnaast is Veo 3 erg sterk in het 'begrijpen' of 'bewust zijn' van fysica. Veo 3 lijkt goed te begrijpen hoe objecten en materialen horen te bewegen.
Ondanks dat Wan 2.2 niet beter is dan Veo 3, is het model wel beter dan ik had verwacht. En het model is ook, in mijn ervaring, beter dan Sora van OpenAI. Het is al heel bijzonder dat zo'n krachtig model gewoon vrij beschikbaar is voor iedereen om te gebruiken, en al helemaal als je beseft dat het zo krachtig is. Waarschijnlijk is het lokaal draaien van het model voor de meeste mensen waarschijnlijk nog wel te complex of te onpraktisch.
Bonus: Len op (Mid)journey
Ook Midjourney heeft sinds enkele maanden een video-generator. Ik kon het niet laten om ook hiermee nog een poging te wagen om Len zijn machinistendroom in vervulling te laten gaan. En het resultaat is de perfecte manier om dit blogartikel af te sluiten.
Kijk hem eens gaan!

